
publications
... and preprints
2025
- arXivMatthew Finlayson , Xiang Ren, and Swabha SwayamdiptaUnder Review, 2025
The ubiquity of closed-weight language models with public-facing APIs has generated interest in forensic methods, both for extracting hidden model details (e.g., parameters) and for identifying models by their outputs. One successful approach to these goals has been to exploit the geometric constraints imposed by the language model architecture and parameters. In this work, we show that a lesser-known geometric constraint–namely, that language model outputs lie on the surface of a high-dimensional ellipse–functions as a signature for the model and can be used to identify the source model of a given output. This ellipse signature has unique properties that distinguish it from existing model-output association methods like language model fingerprints. In particular, the signature is hard to forge: without direct access to model parameters, it is practically infeasible to produce log-probabilities (logprobs) on the ellipse. Secondly, the signature is naturally occurring, since all language models have these elliptical constraints. Thirdly, the signature is self-contained, in that it is detectable without access to the model inputs or the full weights. Finally, the signature is compact and redundant, as it is independently detectable in each logprob output from the model. We evaluate a novel technique for extracting the ellipse from small models and discuss the practical hurdles that make it infeasible for production-scale models. Finally, we use ellipse signatures to propose a protocol for language model output verification, analogous to cryptographic symmetric-key message authentication systems.
- arXivUnder Review, 2025
Micro-benchmarking offers a solution to the often prohibitive time and cost of language model development: evaluate on a very small subset of existing benchmarks. Can these micro-benchmarks, however, rank models as consistently as the full benchmarks they replace? And can they rank models more consistently than selecting a random subset of data points? In many scenarios, we find that the answer is no. We introduce a meta-evaluation measure for micro-benchmarking which investigates how well a micro-benchmark can rank two models as a function of their performance difference on the full benchmark. This approach can determine which model pairs can be ranked correctly by a micro-benchmark, allowing for a finer-grained analysis of the trade-off between micro-benchmark size and reliability. Prior work has suggested selecting as few as 10 examples; we find that no micro-benchmarking method can consistently rank model pairs 3.5 points of accuracy apart on MMLU-Pro or 4 points apart on BIG-bench Hard. In order to consistently rank model pairs with relatively similar performances, we show that often as many as 250 examples must be selected, at which point random sampling is competitive with existing micro-benchmarking methods. When comparing only 8B instruction-tuned models on MMLU-Pro micro-benchmarks with 25 examples, we find that more than half of pairwise comparisons are not likely to be preserved. Our work provides actionable guidance for both micro-benchmark users and developers in navigating the trade-off between evaluation efficiency and reliability.
- arXivUnder Review, 2025
When people query Vision-Language Models (VLMs) but cannot see the accompanying visual context (e.g. for blind and low-vision users), augmenting VLM predictions with natural language explanations can signal which model predictions are reliable. However, prior work has found that explanations can easily convince users that inaccurate VLM predictions are correct. To remedy undesirable overreliance on VLM predictions, we propose evaluating two complementary qualities of VLM-generated explanations via two quality scoring functions. We propose Visual Fidelity, which captures how faithful an explanation is to the visual context, and Contrastiveness, which captures how well the explanation identifies visual details that distinguish the model’s prediction from plausible alternatives. On the A-OKVQA and VizWiz tasks, these quality scoring functions are better calibrated with model correctness than existing explanation qualities. We conduct a user study in which participants have to decide whether a VLM prediction is accurate without viewing its visual context. We observe that showing our quality scores alongside VLM explanations improves participants’ accuracy at predicting VLM correctness by 11.1%, including a 15.4% reduction in the rate of falsely believing incorrect predictions. These findings highlight the utility of explanation quality scores in fostering appropriate reliance on VLM predictions.
- NeurIPSMurtaza Nazir, Matthew Finlayson , John X. Morris, Xiang Ren, and Swabha SwayamdiptaProc. of NeurIPS, 2025
Language model inversion seeks to recover hidden prompts using only language model outputs. This capability has implications for security and accountability in language model deployments, such as leaking private information from an API-protected language model’s system message. We propose a new method – prompt inversion from logprob sequences (PILS) – that recovers hidden prompts by gleaning clues from the model’s next-token probabilities over the course of multiple generation steps. Our method is enabled by a key insight: The vector-valued outputs of a language model occupy a low-dimensional subspace. This enables us to losslessly compress the full next-token probability distribution over multiple generation steps using a linear map, allowing more output information to be used for inversion. Our approach yields massive gains over previous state-of-the-art methods for recovering hidden prompts, achieving 2–3.5 times higher exact recovery rates across test sets, in one case increasing the recovery rate from 17% to 60%. Our method also exhibits surprisingly good generalization behavior; for instance, an inverter trained on 16 generations steps gets 5–27 points higher prompt recovery when we increase the number of steps to 32 at test time. Furthermore, we demonstrate strong performance of our method on the more challenging task of recovering hidden system messages. We also analyze the role of verbatim repetition in prompt recovery and propose a new method for cross-family model transfer for logit-based inverters. Our findings show that next-token probabilities are a considerably more vulnerable attack surface for inversion attacks than previously known.
- CoLMConference on Language Modeling, 2025
Language model developers typically filter out high-risk content – such as toxic or copyrighted text – from their pre-training data to prevent models from generating similar outputs. However, removing such data altogether limits models’ ability to recognize and appropriately respond to harmful or sensitive content. In this paper, we introduce Selective Loss to Understand but Not Generate (SLUNG), a pre-training paradigm through which models learn to understand high-risk data without learning to generate it. Instead of uniformly applying the next-token prediction loss, SLUNG selectively avoids incentivizing the generation of high-risk tokens while ensuring they remain within the model’s context window. As the model learns to predict low-risk tokens that follow high-risk ones, it is forced to understand the high-risk content. Through our experiments, we show that SLUNG consistently improves models’ understanding of high-risk data (e.g., ability to recognize toxic content) without increasing its generation (e.g., toxicity of model responses). Overall, our SLUNG paradigm enables models to benefit from high-risk text that would otherwise be filtered out.
- CoLMCOLM Workshop on Test-time Scaling and Reasoning Models (ScaLR@COLM) / NeurIPS Workshop on Efficient Reasoning, 2025
Inference-time scaling methods improve language model performance, but existing methods lack the flexibility to synthesize information across multiple long-form generation samples. We introduce Consensus Graphs (CONGRS), a flexible DAG-based data structure that represents shared content and semantic variation across a set of LM responses to the same prompt. Constructing CONGRS relies on lightweight lexical multiple sequence alignment supplemented by targeted usage of a secondary LM judge, which reduces reliance on LM judges by more than 80% compared to other methods. Our experiments show that synthesizing responses from CONGRS improves factual precision on a biography generation task by up to 32% over an average response. We apply our approach to the MATH and AIME reasoning tasks and find an improvement over self-verification and majority vote baselines by up to 6 points of accuracy. CONGRS are a promising way to efficiently use the information provided by inference-time scaling.
- NeurIPSNeurIPS Workshop on LLM Evaluation, 2025
Despite the successes of language models, their evaluation remains a daunting challenge for new and existing tasks. We consider the task of text simplification, commonly used to improve information accessibility, where evaluation faces two major challenges. First, the data in existing benchmarks might not reflect the capabilities of current language models on the task, often containing disfluent, incoherent, or simplistic examples. Second, existing human ratings associated with the benchmarks often contain a high degree of disagreement, resulting in inconsistent ratings; nevertheless, existing metrics still have to show higher correlations with these imperfect ratings. As a result, evaluation for the task is not reliable and does not reflect expected trends (e.g., more powerful models being assigned higher scores). We address these challenges for the task of text simplification through three contributions. First, we introduce SynthSimpliEval, a synthetic benchmark for text simplification featuring simplified sentences generated by models of varying sizes. Through a pilot study, we show that human ratings on our benchmark exhibit high inter-annotator agreement and reflect the expected trend: larger models produce higher-quality simplifications. Second, we show that auto-evaluation with a panel of LLM judges (LLMs-as-a-jury) often suffices to obtain consistent ratings for the evaluation of text simplification. Third, we demonstrate that existing learnable metrics for text simplification benefit from training on our LLMs-as-a-jury-rated synthetic data, closing the gap with pure LLMs-as-a-jury for evaluation. Overall, through our case study on text simplification, we show that a reliable evaluation requires higher quality test data, which could be obtained through synthetic data and LLMs-as-a-jury ratings.
- NeurIPSJaspreet Ranjit , Hyundong J. Cho, Claire J. Smerdon, Yoonsoo Nam , Myles Phung, Jonathan May, John R. Blosnich, and Swabha SwayamdiptaEAAMO / NeurIPS Workshop on GenAI for Health, 2025
The National Violent Death Reporting System (NVDRS) documents information about suicides in the United States, including free text narratives (e.g., circumstances surrounding a suicide). In a demanding public health data pipeline, annotators manually extract structured information from death investigation records following extensive guidelines developed painstakingly by experts. In this work, we facilitate data-driven insights from the NVDRS data to support the development of novel suicide interventions by investigating the value of language models (LMs) as efficient assistants to these (a) data annotators and (b) experts. We find that LM predictions match existing data annotations about 85% of the time across 50 NVDRS variables. In the cases where the LM disagrees with existing annotations, expert review reveals that LM assistants can surface annotation discrepancies 38% of the time. Finally, we introduce a human-in-the-loop algorithm to assist experts in efficiently building and refining guidelines for annotating new variables by allowing them to focus only on providing feedback for incorrect LM predictions. We apply our algorithm to a real-world case study for a new variable that characterizes victim interactions with lawyers and demonstrate that it achieves comparable annotation quality with a laborious manual approach. Our findings provide evidence that LMs can serve as effective assistants to public health researchers who handle sensitive data in high-stakes scenarios.
- NeurIPSRisha Surana , Qinyuan Ye, and Swabha SwayamdiptaNeurIPS Workshop on LLM Evaluation, 2025
Emergency responders managing hazardous material HAZMAT incidents face critical, time-sensitive decisions, manually navigating extensive chemical guidelines. We investigate whether today’s language models can assist responders by rapidly and reliably understanding critical information, identifying hazards, and providing responses. We introduce the Chemical Emergency Response Evaluation Framework (ChEmREF), a new benchmark comprising questions on 1,035 HAZMAT chemicals from the Emergency Response Guidebook and the PubChem Database. ChEmREF is organized into three tasks: (1) translation of chemical representation between structured and unstructured forms (e.g., converting C2H6O to ethanol), (2) emergency response generation (e.g., recommending appropriate evacuation distances) and (3) domain knowledge question answering from chemical safety and certification exams. Our best evaluated models received an exact match of 68.0% on unstructured HAZMAT chemical representation translation, a LLM Judge score of 52.7% on incident response recommendations, and a multiple-choice accuracy of 63.9% on HAMZAT examinations. These findings suggest that while language models show potential to assist emergency responders in various tasks, they require careful human oversight due to their current limitations.
- EMNLPAtharva Kulkarni , Yuan Zhang, Joel Ruben Antony Moniz, Xiou Ge, Bo-Hsiang Tseng, Dhivya Piraviperumal, Swabha Swayamdipta , and Hong YuFindings of EMNLP, 2025
Hallucinations pose a significant obstacle to the reliability and widespread adoption of language models, yet their accurate measurement remains a persistent challenge. While many task- and domain-specific metrics have been proposed to assess faithfulness and factuality concerns, the robustness and generalization of these metrics are still untested. In this paper, we conduct a large-scale empirical evaluation of 6 diverse sets of hallucination detection metrics across 4 datasets, 37 language models from 5 families, and 5 decoding methods. Our extensive investigation reveals concerning gaps in current hallucination evaluation: metrics often fail to align with human judgments, take an overtly myopic view of the problem, and show inconsistent gains with parameter scaling. Encouragingly, LLM-based evaluation, particularly with GPT-4, yields the best overall results, and mode-seeking decoding methods seem to reduce hallucinations, especially in knowledge-grounded settings. These findings underscore the need for more robust metrics to understand and quantify hallucinations, and better strategies to mitigate them.
- EMNLPBrihi Joshi , Xiang Ren, Swabha Swayamdipta , Rik Koncel-Kedziorski, and Tim PaekFindings of EMNLP, 2025
Language models prompted with a user description or persona can predict a user’s preferences and opinions, but existing approaches to building personas – based solely on a user’s demographic attributes and/or prior judgments – fail to capture the underlying reasoning behind said user judgments. We introduce PB&J (Psychology of Behavior and Judgments), a framework that improves LLM personas by incorporating rationales of why a user might make specific judgments. These rationales are LLM-generated, and aim to reason about a user’s behavior on the basis of their experiences, personality traits or beliefs. This is done using psychological scaffolds – structured frameworks grounded in theories such as the Big 5 Personality Traits and Primal World Beliefs – that help provide structure to the generated rationales. Experiments on public opinion and movie preference prediction tasks demonstrate that LLM personas augmented with PB&J rationales consistently outperform methods using only a user’s demographics and/or judgments. Additionally, LLM personas constructed using scaffolds describing user beliefs perform competitively with those using human-written rationales.
- ACLXinyue Cui , Johnny Tian-Zheng Wei, Swabha Swayamdipta , and Robin JiaFindings of ACL, 2025
Data watermarking in language models injects traceable signals, such as specific token sequences or stylistic patterns, into copyrighted text, allowing copyright holders to track and verify training data ownership. Previous data watermarking techniques primarily focus on effective memorization after pretraining, while overlooking challenges that arise in other stages of the LLM pipeline, such as the risk of watermark filtering during data preprocessing, or potential forgetting through post-training, or verification difficulties due to API-only access. We propose a novel data watermarking approach that injects coherent and plausible yet fictitious knowledge into training data using generated passages describing a fictitious entity and its associated attributes. Our watermarks are designed to be memorized by the LLM through seamlessly integrating in its training data, making them harder to detect lexically during preprocessing. We demonstrate that our watermarks can be effectively memorized by LLMs, and that increasing our watermarks’ density, length, and diversity of attributes strengthens their memorization. We further show that our watermarks remain robust throughout LLM development, maintaining their effectiveness after continual pretraining and supervised finetuning. Finally, we show that our data watermarks can be evaluated even under API-only access via question answering.
- ACLBrihi Joshi , Keyu He , Sahana Ramnath, Sadra Sabouri, Kaitlyn Zhou, Souti Chattopadhyay, Swabha Swayamdipta , and Xiang RenFindings of ACL, 2025
Language models today are widely used in education, yet their ability to tailor responses for learners with varied informational needs and knowledge backgrounds remains under-explored. To this end, we introduce ELI-Why, a benchmark of 13.4K "Why" questions to evaluate the pedagogical capabilities of language models. We then conduct two extensive human studies to assess the utility of language model-generated explanatory answers (explanations) on our benchmark, tailored to three distinct educational grades: elementary, high-school and graduate school. In our first study, human raters assume the role of an "educator" to assess model explanations’ fit to different educational grades. We find that GPT-4-generated explanations match their intended educational background only 50% of the time, compared to 79% for lay human-curated explanations. In our second study, human raters assume the role of a learner to assess if an explanation fits their own informational needs. Across all educational backgrounds, users deemed GPT-4-generated explanations 20% less suited on average to their informational needs, when compared to explanations curated by lay people. Additionally, automated evaluation metrics reveal that explanations generated across different language model families for different informational needs remain indistinguishable in their grade-level, limiting their pedagogical effectiveness.
2024
- EMNLP
 Sayan Ghosh , Tejas Srinivasan, and Swabha SwayamdiptaIn Findings of EMNLP , 2024
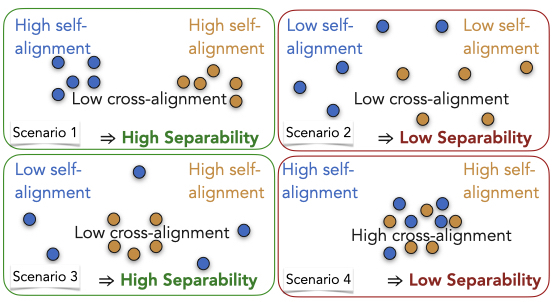
Sayan Ghosh , Tejas Srinivasan, and Swabha SwayamdiptaIn Findings of EMNLP , 2024Human evaluation of generated language through pairwise preference judgments is pervasive. However, under common scenarios, such as when generations from a model pair are very similar, or when stochastic decoding results in large variations in generations, it results in inconsistent preference ratings. We address these challenges by introducing a meta-evaluation measure, separability, which estimates how suitable a test instance is for pairwise preference evaluation. For a candidate test instance, separability samples multiple generations from a pair of models, and measures how distinguishable the two sets of generations are. Our experiments show that instances with high separability values yield more consistent preference ratings from both human- and auto-raters. Further, the distribution of separability allows insights into which test benchmarks are more valuable for comparing models. Finally, we incorporate separability into ELO ratings, accounting for how suitable each test instance might be for reliably ranking LLMs. Overall, separability has implications for consistent, efficient and robust preference evaluation of LLMs with both human- and auto-raters.
- EMNLP
 Jaspreet Ranjit , Brihi Joshi , Rebecca Dorn, Laura Petry, Olga Koumoundouros, Jayne Bottarini , Peichen Liu, Eric Rice, and Swabha SwayamdiptaIn Proceedings of EMNLP , 2024
Jaspreet Ranjit , Brihi Joshi , Rebecca Dorn, Laura Petry, Olga Koumoundouros, Jayne Bottarini , Peichen Liu, Eric Rice, and Swabha SwayamdiptaIn Proceedings of EMNLP , 2024Outstanding Paper Award @ EMNLP 2024; Jaspreet received a best poster award at USC CAIS’s annual symposium, ShowCAIS in Spring 2024.
Homelessness in the U.S. is widespread; individual beliefs and attitudes towards homelessness—often expressed on social media are complex and nuanced (e.g. critical as well as sympathetic). Such attitudes can be challenging to summarize at scale, obfuscating the broader public opinion which advocacy organizations use to guide public policy and reform efforts. Our work proposes an approach to enable a large-scale study on homelessness via two major contributions. First, with the help of domain experts in social work and their trainees, we characterize Online Attitudes towards Homelessness in nine hierarchical frames (OATH-Frames) on a collection of 4K social media posts. Further, in an effort to ease the annotation of these frames, we employ GPT-4 as an LLM assistant to the experts; GPT-4 + Expert annotation presents an attractive trade off owing to a 6.5× speedup in annotation time despite only incurring a 2 point F1 difference in annotation performance. Our effort results in a collection of 8K social media posts labeled by domain and trained experts (with and without GPT-4 assistance). Second, using predicted OATH-Frames on a Flan-T5-Large model trained on our data, we perform a large-scale analysis on 2.4M posts on homelessness. We find that posts that contain mentions of west coast states express more harmful generalizations of people experiencing homelessness (PEH) compared to posts about east coast states. We also find marked differences in attitudes across vulnerable populations as they are compared to PEH as being either more or less deserving of aid.
- EMNLP
 Aryan Gulati , Xingjian Dong , Carlos Hurtado, Sarath Shekkizhar, Swabha Swayamdipta , and Antonio OrtegaIn Findings of EMNLP , 2024
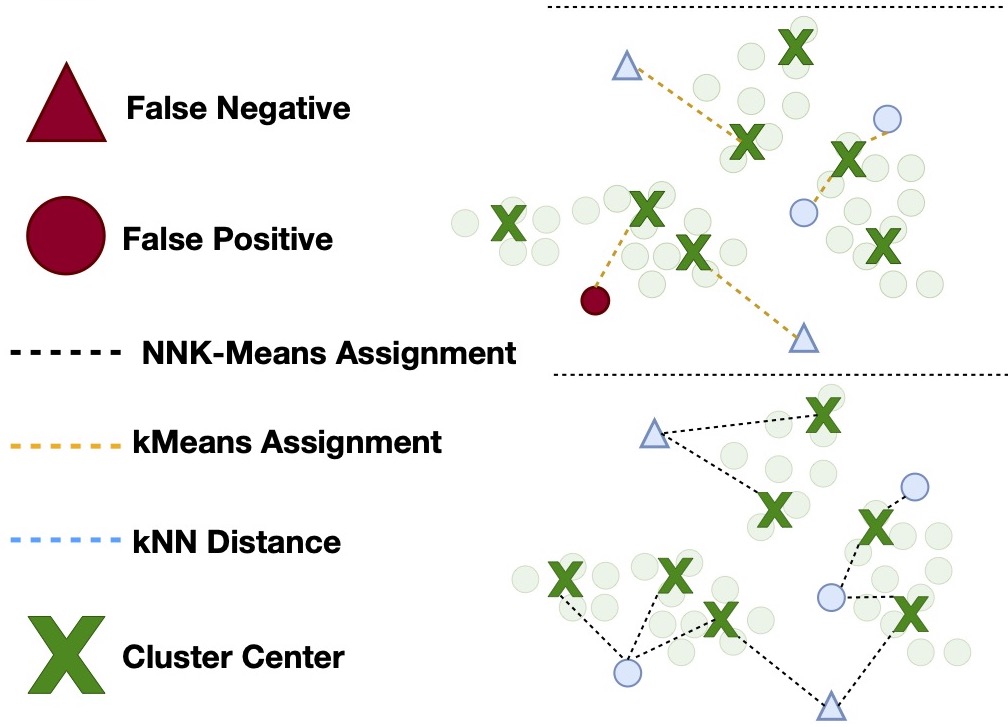
Aryan Gulati , Xingjian Dong , Carlos Hurtado, Sarath Shekkizhar, Swabha Swayamdipta , and Antonio OrtegaIn Findings of EMNLP , 2024As language models become more general purpose, increased attention needs to be paid to detecting out-of-distribution (OOD) instances, i.e., those not belonging to any of the distributions seen during training. Existing methods for detecting OOD data are computationally complex and storage-intensive. We propose a novel soft clustering approach for OOD detection based on non-negative kernel regression. Our approach greatly reduces computational and space complexities (up to 11\times improvement in inference time and 87% reduction in storage requirements) and outperforms existing approaches by up to 4 AUROC points on four different benchmarks. We also introduce an entropy-constrained version of our algorithm, which leads to further reductions in storage requirements (up to 97% lower than comparable approaches) while retaining competitive performance. Our soft clustering approach for OOD detection highlights its potential for detecting tail-end phenomena in extreme-scale data settings.
- COLM
 Crowd-Calibrator: Can Annotator Disagreement Inform Calibration in Subjective Tasks?Urja Khurana, Eric Nalisnick, Antske Fokkens, and Swabha SwayamdiptaIn Proceedings of COLM , 2024
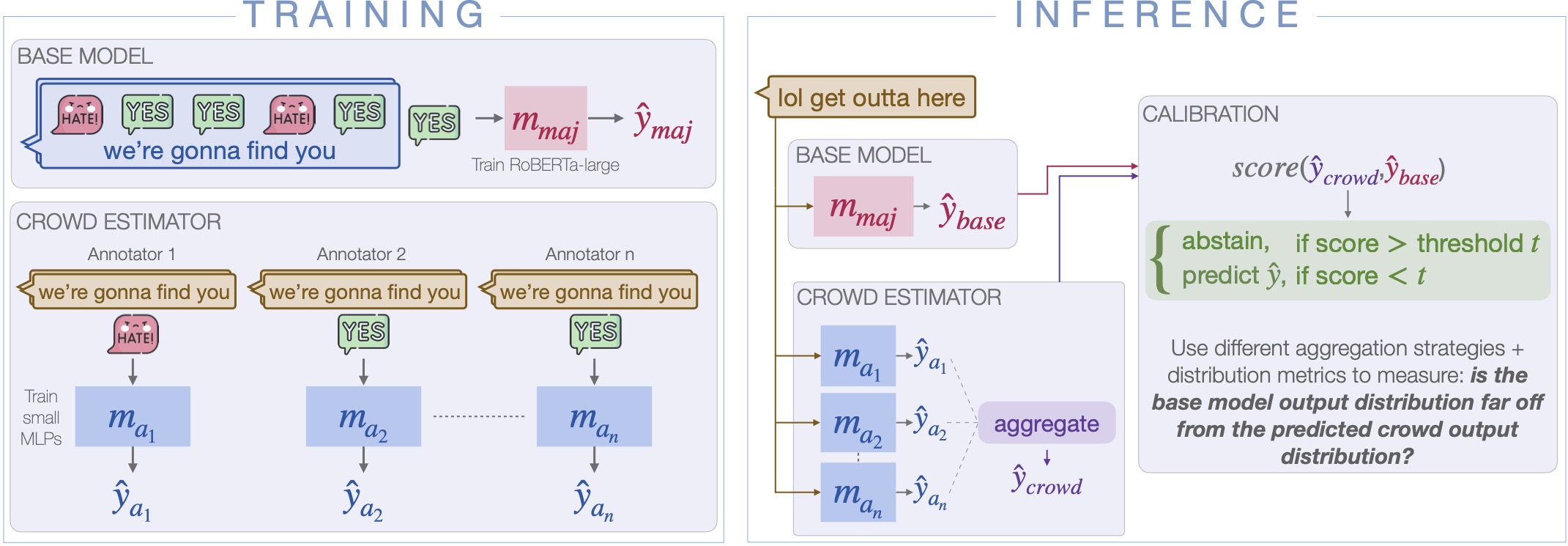
Crowd-Calibrator: Can Annotator Disagreement Inform Calibration in Subjective Tasks?Urja Khurana, Eric Nalisnick, Antske Fokkens, and Swabha SwayamdiptaIn Proceedings of COLM , 2024Subjective tasks in NLP have been mostly relegated to objective ones where the gold label is decided by taking the majority vote, thereby obfuscating annotator disagreement and inherent uncertainty of instances. We argue that that subjectivity should play a role in model decisions, considering a selective prediction setting. However, instead of calibrating confidence purely from the model’s perspective, we calibrate models for subjective tasks based on crowdworker agreement. Our method, Crowd-Calibrator, models annotations from crowdworkers and the distance between crowdworker distribution and the model’s own distribution over labels to inform whether the model should abstain from a decision. On two highly subjective tasks, namely hate speech detection and natural language inference (NLI), our experiments show Crowd-Calibrator either outperforming or achieving competitive performance with selective prediction baselines, highlighting the value of bringing in human decision making into model predictions.
- COLM
 Matthew Finlayson , Xiang Ren, and Swabha SwayamdiptaIn Proceedings of COLM , 2024
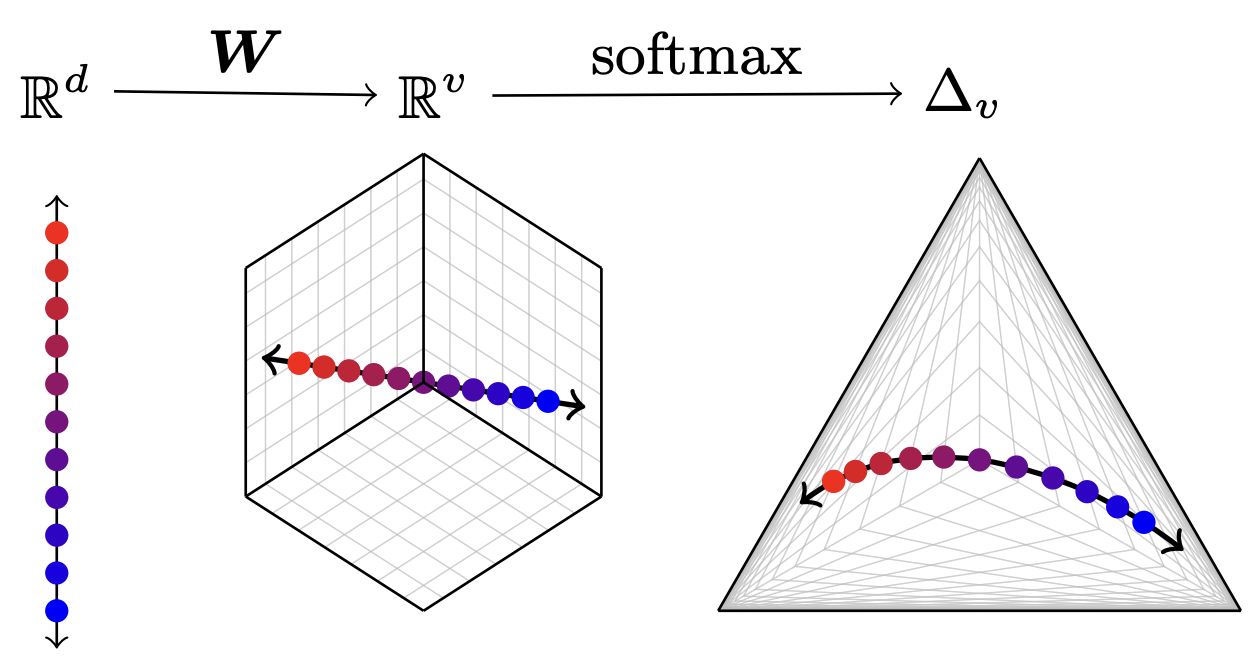
Matthew Finlayson , Xiang Ren, and Swabha SwayamdiptaIn Proceedings of COLM , 2024The commercialization of large language models (LLMs) has led to the common practice of high-level API-only access to proprietary models. In this work, we show that even with a conservative assumption about the model architecture, it is possible to learn a surprisingly large amount of non-public information about an API-protected LLM from a relatively small number of API queries (e.g., costing under $1,000 for OpenAI’s gpt-3.5-turbo). Our findings are centered on one key observation: most modern LLMs suffer from a softmax bottleneck, which restricts the model outputs to a linear subspace of the full output space. We show that this lends itself to a model image or a model signature which unlocks several capabilities with affordable cost: efficiently discovering the LLM’s hidden size, obtaining full-vocabulary outputs, detecting and disambiguating different model updates, identifying the source LLM given a single full LLM output, and even estimating the output layer parameters. Our empirical investigations show the effectiveness of our methods, which allow us to estimate the embedding size of OpenAI’s gpt-3.5-turbo to be about 4,096. Lastly, we discuss ways that LLM providers can guard against these attacks, as well as how these capabilities can be viewed as a feature (rather than a bug) by allowing for greater transparency and accountability.
- ACL
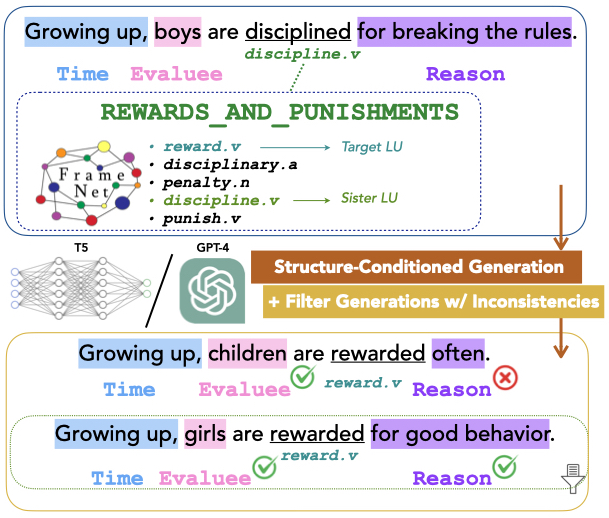 Xinyue Cui , and Swabha SwayamdiptaIn Proceedings of ACL , 2024
Xinyue Cui , and Swabha SwayamdiptaIn Proceedings of ACL , 2024Despite the mounting evidence for generative capabilities of language models in understanding and generating natural language, their effectiveness on explicit manipulation and generation of linguistic structures remain understudied. In this paper, we investigate the task of generating new sentences preserving a given semantic structure, following the FrameNet formalism. We propose a framework to produce novel frame-semantically annotated sentences following an overgenerate-and-filter approach. Our results show that conditioning on rich, explicit semantic information tends to produce generations with high human acceptance, under both prompting and finetuning. Nevertheless, we discover that generated frame-semantic structured data is ineffective at training data augmentation for frame-semantic role labeling. Our study concludes that while generating high-quality, semantically rich data might be within reach, their downstream utility remains to be seen, highlighting the outstanding challenges with automating linguistic annotation tasks.
- ICLR
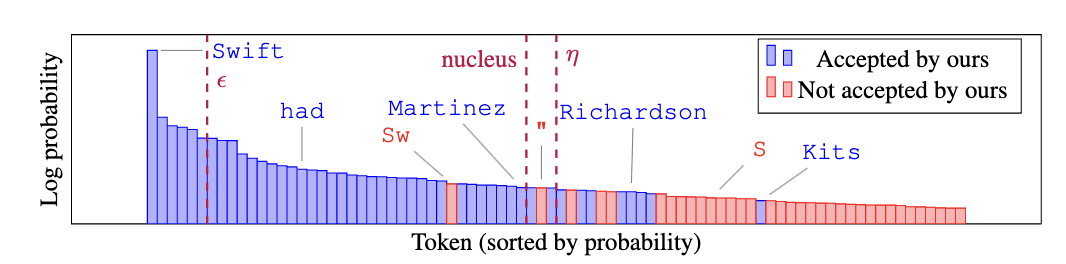 Matthew Finlayson , John Hewitt, Alexander Koller, Swabha Swayamdipta , and Ashish SabharwalIn Proc. of ICLR , 2024
Matthew Finlayson , John Hewitt, Alexander Koller, Swabha Swayamdipta , and Ashish SabharwalIn Proc. of ICLR , 2024Despite their ubiquity in language generation, it remains unknown why truncation sampling heuristics like nucleus sampling are so effective. We provide a theoretical explanation for the effectiveness of the truncation sampling by proving that truncation methods that discard tokens below some probability threshold (the most common type of truncation) can guarantee that all sampled tokens have nonzero true probability. However, thresholds are a coarse heuristic, and necessarily discard some tokens with nonzero true probability as well. In pursuit of a more precise sampling strategy, we show that we can leverage a known source of model errors, the softmax bottleneck, to prove that certain tokens have nonzero true probability, without relying on a threshold. Based on our findings, we develop an experimental truncation strategy and the present pilot studies demonstrating the promise of this type of algorithm. Our evaluations show that our method outperforms its threshold-based counterparts under automatic and human evaluation metrics for low-entropy (i.e., close to greedy) open-ended text generation. Our theoretical findings and pilot experiments provide both insight into why truncation sampling works, and make progress toward more expressive sampling algorithms that better surface the generative capabilities of large language models.
- ICASSP
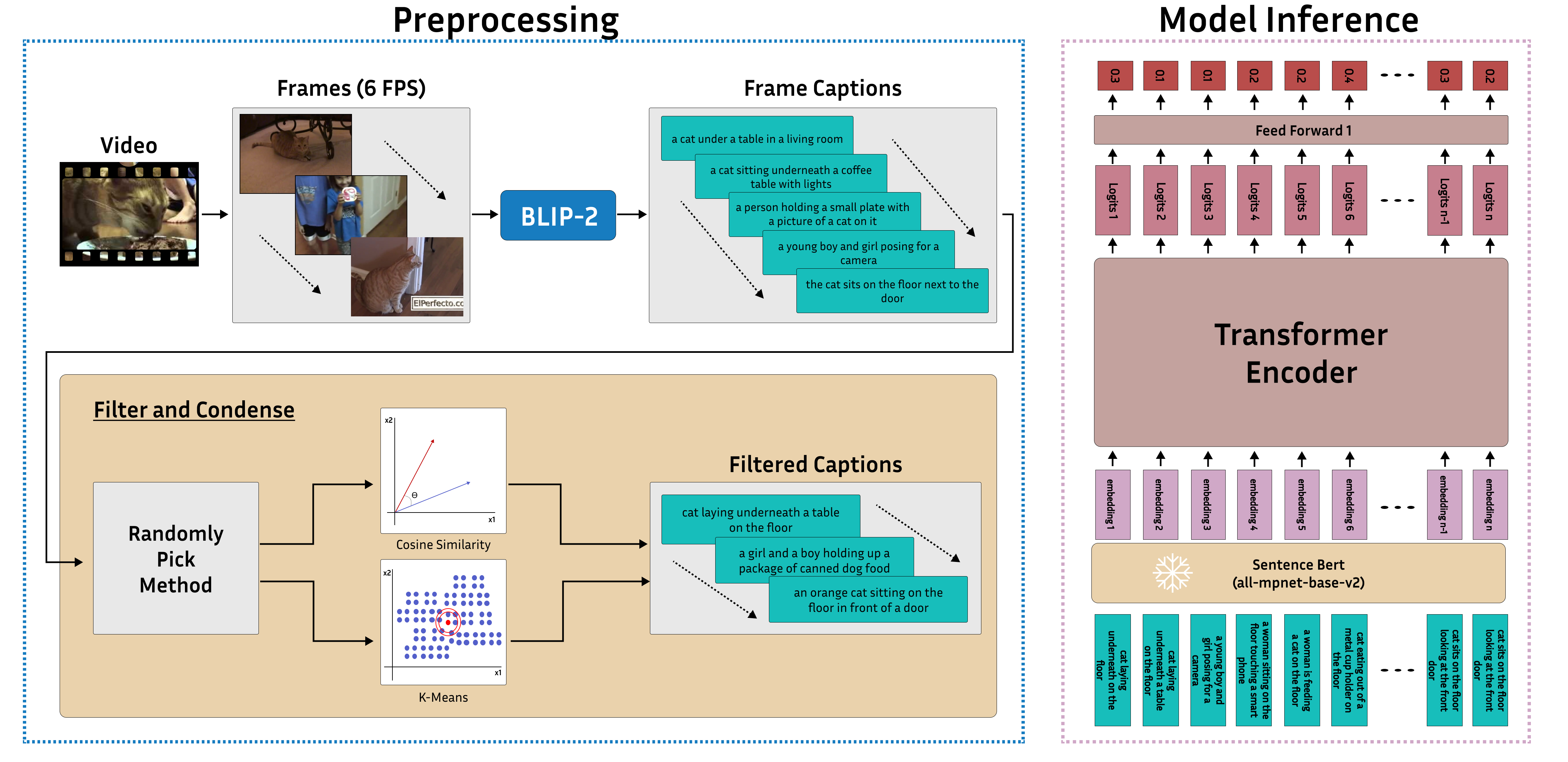 Yoonsoo Nam , Adam Lehavi , Daniel Yang, Digbalay Bose, Swabha Swayamdipta , and Shrikanth NarayananIn Proc. of ICASSP , 2024
Yoonsoo Nam , Adam Lehavi , Daniel Yang, Digbalay Bose, Swabha Swayamdipta , and Shrikanth NarayananIn Proc. of ICASSP , 2024Video summarization remains a huge challenge in computer vision due to the size of the input videos to be summarized. We propose an efficient, language-only video summarizer that achieves competitive accuracy with high data efficiency. Using only textual captions obtained via a zero-shot approach, we train a language transformer model and forego image representations. This method allows us to perform filtration amongst the representative text vectors and condense the sequence. With our approach, we gain explainability with natural language that comes easily for human interpretation and textual summaries of the videos. An ablation study that focuses on modality and data compression shows that leveraging text modality only effectively reduces input data processing while retaining comparable results.







